Van dinsdag 17 mei tot en met donderdag 19 mei vond in Las Vegas de Tableau Conference 22 plaats. De conferentie start met een Keynote, waarin de nieuwe functionaliteiten worden bekend gemaakt, die het komend jaar hun weg zullen vinden naar de verschillende producten van Tableau. Na de Keynote zijn er verspreid over drie dagen vele Breakout sessions. Deze sessions zijn opgedeeld in meerdere categorieën, die grofweg bestaan deze uit Hands-on sessies, Demo Sessies, Customer Story sessies en sessies over Data Culture
Coney Minds is met twee mensen vertegenwoordigd, Ferry Jong en ik. In deze Blog neem ik u mee in de nieuwe functionaliteiten, de lessons learnt en de inspiratie die we tijdens de drie dagen hebben opgedaan om nog betere inzichten in Tableau te kunnen genereren voor onze klanten.
De Keynote
Tijdens de keynote worden we meegenomen in de nieuwe functionaliteiten van Tableau. Hieronder zal ik de, voor ons, belangrijkste functionaliteiten uitlichten.
Tableau Cloud
De eerste belangrijke aankondiging is de wijziging van Tableau Online naar Tableau Cloud (want alles is Cloud tegenwoordig), in feite veranderd er niet wezenlijk niets aan het product, maar het is vanaf Tableau Cloud wel mogelijk om binnen één Cloud-instance meerdere Sites aan te maken, wat voorheen in Online niet mogelijk was. Hierdoor is Tableau Cloud een meer serieuze tegenhanger voor Tableau Server. Naast de mogelijkheid tot Sites op Tableau Cloud komen er ook Accelerators, dit zijn pre-build dashboards die aan bekende databronnen gekoppeld kunnen worden, zodat u direct inzicht heeft in uw data.
Data stories
Data stories is een extensie welke op dashboards kunnen worden toegevoegd en die automatisch een narratief overzicht geeft van de belangrijkste kenmerken van de data op het dashboard. Hierdoor krijgen gebruikers van het dashboard sneller inzicht in de data waar ze naar kijken. Naast dat deze data stories geheel automatisch worden gegenereerd werken ze ook dynamisch samen met de filteringen op het dashboard.
Tableau Model Builder
Straks is het direct vanuit Tableau mogelijk om Machine Learning modellen te bouwen, deze modellen zijn te maken zonder diepgaande kennis van Machine Learning. U kunt straks in een paar klikken lineair- en tree based modellen maken.
Als het model is getraind, dan kunt u eenvoudig de prestaties van uw model monitoren om te beoordelen hoe het model data classificeert en welke key features van belang waren voor de voorspelling. Uiteraard geheel visueel zoals dat in Tableau hoort.
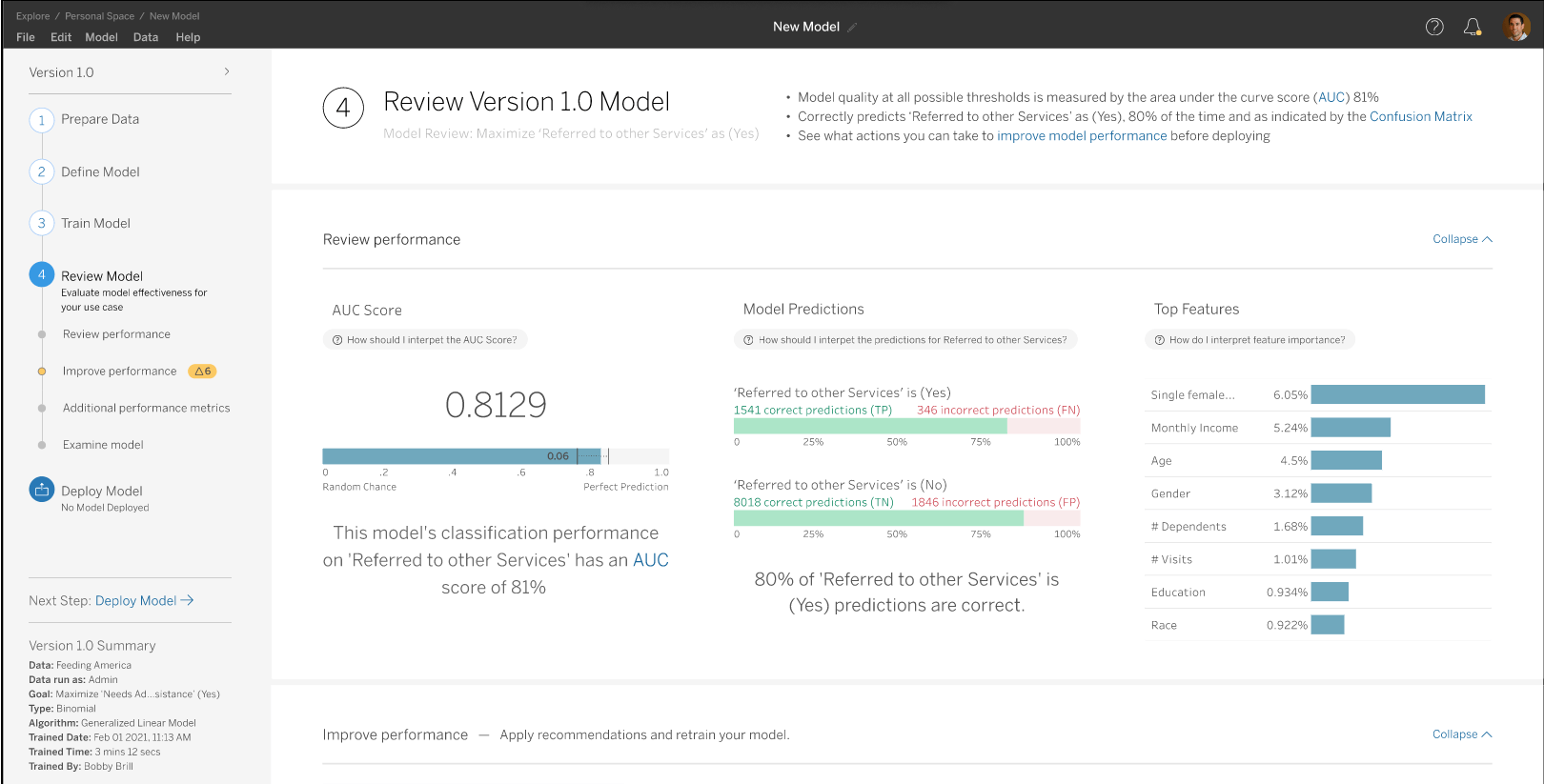
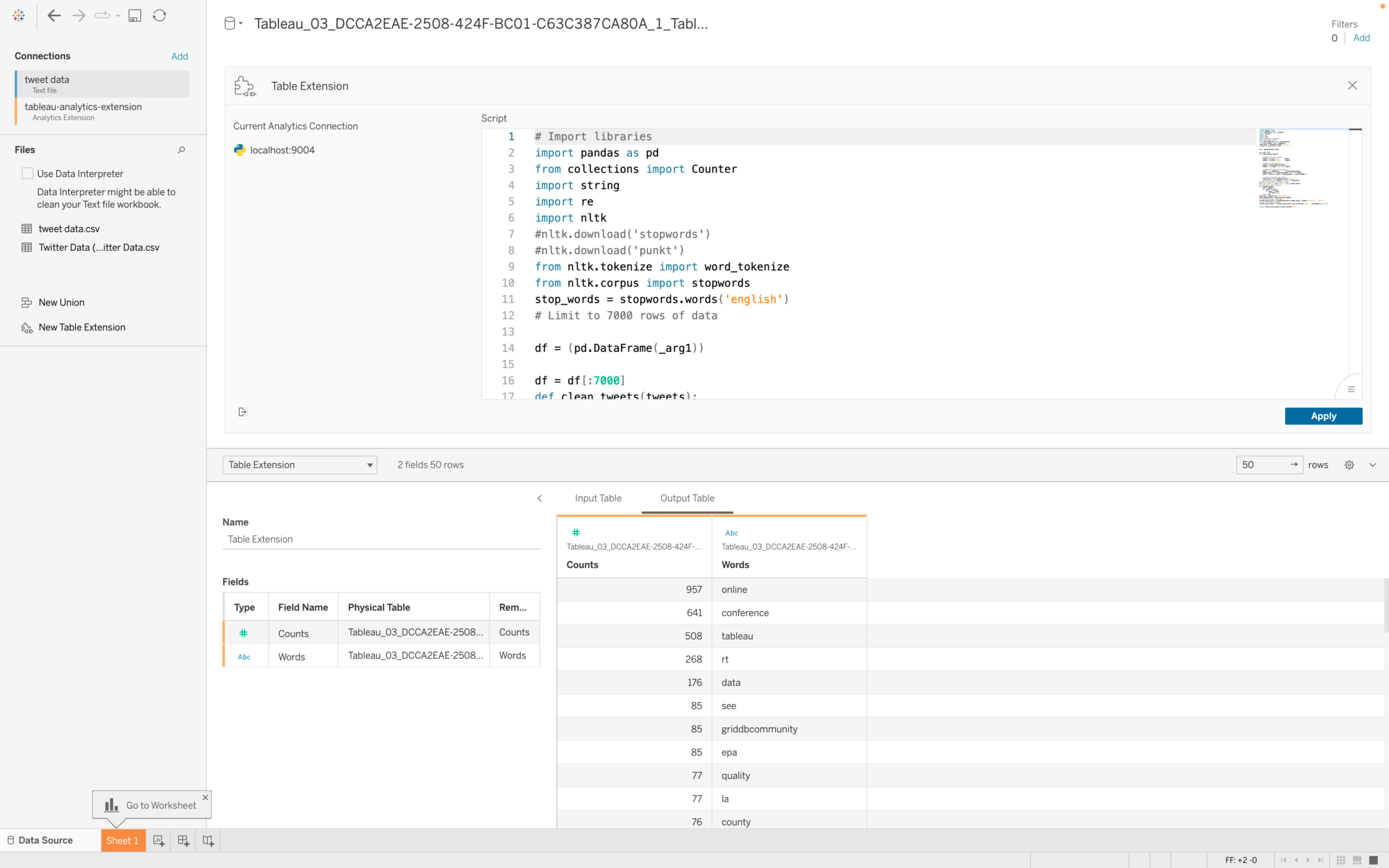
Table Extensions
Met Tableau Extensions kunt u de kracht van Python en R inzetten bij het modelleren van de datasource in Tableau. Hiermee is het mogelijk allerhande complexe berekeningen toe te voegen op uw brondata en een verrijkte datasource te creëren.
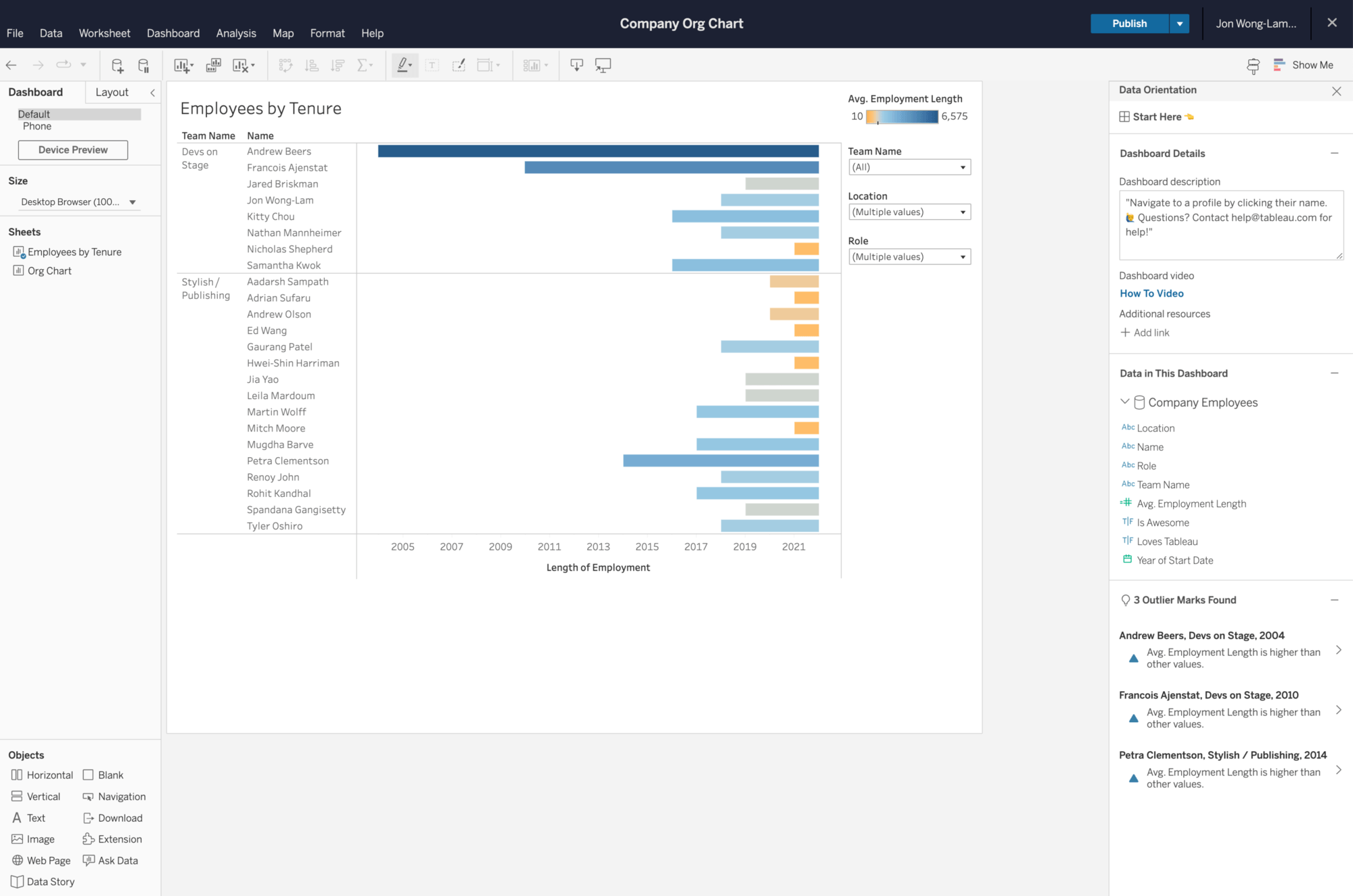
Data orientation Pane
Het Data orientation pane is een handig overzicht van nuttige informatie en bronnen geïntegreerd in het dashboard. Het pane bevat onder andere beschrijvingen, een lijst van gebruikte datasources en velden, een samenvatting hoe de data is gefilterd. Het Pane wordt automatisch bijgewerkt wanneer een gebruiker een specifieke viz of mark selecteert.
De Sessies
Ik heb tijdens de drie dagen meerdere break-out sessies bijgewoond, de ene nuttiger dan de andere, maar iedere sessie biedt weer stof tot nadenken of inspiratie.
In de sessie over ‘Mind the (Data Culture) Gap’ werd nog maar eens bevestigd dat er geen goed of fout is bij het starten om een data gedreven organisatie te worden. Snel van start gaan door bekende dashboards door een externe specialist te laten bouwen in Tableau kan een mooie kickstart geven, met het risico dat de dashboards niet verder groeien, omdat er geen kennis in de organisatie is. Daar tegenover staat langzamer starten door eigen mensen te trainen en zelf de dashboards te laten bouwen. Dit kost aan het begin een grotere investering in tijd en de eerste dashboards worden later opgeleverd, maar de kans dat u daarna dashboards blijft ontwikkelen gericht op nieuwe vragen die ontstaan, is wel vele malen groter, omdat u de kennis nu zelf binnen uw organisatie hebt.
De laatste sessie van dag is de Keynote van professor Hannay Fry. Haar presentatie gaat over Machine Learning waarin ze kiest voor een opvallende invalshoek. Machine Learning is niet altijd beter dan wat we al kennen. Zo blijkt dat veel voorspellingen op basis van enorme datasets met vele features niet eens beter presteren dan de ouderwetse voorspellingen op basis van veel minder data en veel minder features.
Op het gebied van borstkanker wordt tegenwoordig ook veel ML ingezet om de gemaakt foto’s te analyseren op het aanwezig zijn van borstkanker. Deze modellen werken heel erg goed, vaak wordt borstkanker op deze manier gevonden. Goed nieuws zou je zeggen, maar… het blijkt dat veel vrouwen een vorm van borstkanker hebben, die gedurende hun leven nooit zo ernstig wordt dat behandeling nodig zou zijn. Deze ‘gevallen’ worden door middel van de ML-modellen nu wel gevonden, met alle daarbij komende gevolgen van dien. Lange behandeltrajecten, vele soms schadelijke medicijn-kuren, levens die op hun kop staan, etc. Dit is dus niet in alle gevallen noodzakelijk.
Zoals Uncle Ben uit Spiderman al zei: “With great power comes great responsibility.” Ga dus wijs om met het inzetten van Machine Learning. Gebruik het niet omdat het kan, maar zet het alleen in als andere middelen niet het gewenste resultaat hebben.
Dag twee start ik met een sessie over Advanced Server Management. Tableau biedt extra tools om Tableau server goed te beheren en veilig te houden. Voor nu nog niet nodig, maar het aantal gebruikers op onze Tableau Server groeit gestaag, dus er komt een moment dat we deze tools wel nodig hebben om onze klanten die geweldige Tableau ervaring te kunnen blijven bieden als dat ze nu gewend zijn op onze server.
Daarna ga ik verder met een demo sessie over Machine Learning modelling in Tableau, een indrukwekkende tool, welke het gebruik van ML zeker kan versnellen, de praktijk zal uitwijzen hoe bruikbaar dit zal zijn. Wij zullen onze Machine Learning specialist Liv Harkes hier zeker naar laten kijken.
Op dag drie is voor mij de belangrijkste sessie de hands-on sessie over het gebruik van de Hyper api en de Hyper Update api. Twee api’s welke gebruikt kunnen worden om direct vanuit de code hyper files te uploaden naar Tableau Server, en deze files aan te vullen met nieuwe data. Hierdoor is het mogelijk om verschillende tussenstappen uit het proces te halen. Geen datasources eerst updaten in Tableau Desktop en dan uploaden naar de server, geen data eerst in een Database opslaan en de datasource aan de database koppelen, maar de data direct updaten in de geüploade datasource op Tableau server.
Deze api’s gaan een grote waarde hebben voor de Dashboards welke we hebben draaien voor onze Business Analytics klanten, zij kunnen straks op basis van de door ons aangeleverde analyses, in bijvoorbeeld Python, direct hun dashboard zelf uploaden dit verbetert de ervaring.
Hierboven heb ik slechts een bloemlezing gegeven van de highlights uit de sessies. Verbeteringen welke direct impact kunnen hebben op hoe wij als Coney Minds met Tableau kunnen werken of hoe onze klanten een betere ervaring krijgen op onze Tableau Server.
Al met al hebben we de afgelopen week voldoende inspiratie opgedaan om het komende jaar nog gavere, nog betere, nog robuustere en nog diepgaandere inzichten in Tableau te kunnen bouwen voor onze klanten. Mijn Top 3 van features: 1. De Hyper (update) api, 2. Ml Model Builder in Tableau, en 3. De Table Extensions waarmee u Python kan inzetten om de databron te verrijken/ bewerken.
Benieuwd wat Coney Minds voor uw organisatie kan betekenen met Tableau? Neem dan gerust contact op met Ferry of mijzelf, wij kunnen u er alles over vertellen.
